A Data Lineage Tools Comparison Framework for Engineering Leaders

Selecting a data lineage tool is a critical infrastructure decision, not a simple procurement exercise. The right choice slashes incident resolution times by up to 60%, simplifies compliance audits, and builds trust in your data assets. The wrong choice creates technical debt, delivers incomplete lineage graphs, and buckles under the load of modern platforms like Snowflake and Databricks. For engineering leaders, the challenge is to cut through marketing hype and find a solution that delivers tangible operational value within a complex, real-world data stack.
This guide provides a practical framework for that evaluation. It moves past feature checklists to analyze how different tools perform against common engineering hurdles:
- Untangling complex SQL transformations buried in data warehouses like Snowflake or BigQuery.
- Tracking data flow across multi-cloud environments (AWS, Azure, GCP).
- Integrating seamlessly with the modern data stack, including dbt and Airflow.
The decision is not just about features; it’s about aligning a tool’s core architecture with your primary business problem—be it operational stability, data governance, or change management.
The Shift to Automated, Parser-Based Lineage
The market has made its decision: automation is the only viable path forward for data lineage. Manual, diagram-based approaches are obsolete. Automated platforms capture lineage by parsing code and metadata, providing end-to-end visibility without forcing engineers into the soul-crushing work of manual documentation. According to DataEngineeringCompanies.com’s analysis of 86 data engineering firms, teams that adopt automated lineage resolve data quality incidents 40-60% faster than those relying on manual methods.
This shift is a direct response to the complexity of modern data platforms. With the majority of enterprises running multi-cloud strategies, automatically tracing transformations across SQL queries, Python scripts, and BI tools is a baseline requirement, not a luxury.
Comparing Lineage Tool Categories: An Architectural Choice
Your first decision point is choosing the architectural approach that best fits your needs. This single choice defines the tool’s capabilities, its limitations, and its value to your organization.
| Category | Primary Strength | Best For |
|---|---|---|
| Automated Parsers | Deep, technical, column-level lineage | Engineering teams needing root cause analysis and impact analysis. |
| Catalog-Driven | Rich business context and governance | Enterprise-wide governance, compliance, and data discovery. |
| Open-Source | Maximum flexibility and no license cost | Teams with strong engineering resources to build custom solutions. |
This comparison provides the context needed to select a tool that aligns with both your high-level data governance strategy and the day-to-day operational reality of your engineering team.
Architectural Deep Dive: Automated vs. Catalog-Driven Lineage
The most critical differentiator in data lineage tools is how lineage is captured. This is not a minor technical detail; it defines the tool’s accuracy, scalability, and the human effort required to maintain it. The choice is between two philosophies: automated, code-parsing systems and manual, catalog-driven approaches. The right fit depends entirely on the problem you need to solve.
Automated, Parser-Based Architecture
Automated tools act as code detectives. They connect directly to your data stack—databases, transformation layers like dbt, BI platforms, and source code repositories. By actively scanning and parsing SQL query logs, transformation scripts, and BI tool metadata, these platforms programmatically construct a detailed, column-level map of the data’s journey.
- Who it’s for: Technical teams—data engineers, analytics engineers, and BI developers.
- Best at: Root cause analysis and impact analysis. When a critical dashboard breaks, an engineer can use automated lineage to instantly trace the problem upstream through dozens of complex transformations.
- Main benefit: You get granular, column-level lineage with minimal manual upkeep after initial setup. This approach scales across the most complex data ecosystems.
- The catch: Initial configuration can be complex, requiring broad permissions to access and parse metadata. The resulting lineage map is a “noisy” but accurate reflection of the technical reality, often lacking immediate business context.
Automated lineage provides speed and precision for the people building and fixing data pipelines. It is designed to answer “What broke this pipeline?” in minutes, not hours, by showing the exact code and column that caused the failure. This is a foundational capability for achieving data observability.
Manual and Catalog-Driven Architecture
In this model, lineage is not discovered; it is declared. These tools, often part of a larger data catalog, prioritize business context. Data stewards and owners manually draw connections between data assets, linking technical tables and columns to business glossary entries, governance policies, and ownership records.
- Who it’s for: Business users, data stewards, compliance officers, and auditors.
- Best at: Enterprise data governance and compliance reporting. The goal is to give non-technical stakeholders a trusted, high-level view of where sensitive data comes from and how it is used.
- Main benefit: The output is a rich, business-centric lineage map that is easy for anyone to understand. It excels at linking technical assets to the business rules and regulations that govern them, which is critical for understanding complex ETL data pipelines from a governance perspective.
- The catch: This is a manual, labor-intensive process. It does not scale without a fully staffed data governance team. The lineage, often only at the table or file level, becomes outdated the moment a developer changes a pipeline without updating the catalog.
Architectural Showdown: A Clear Choice
The differences in philosophy lead to vastly different outcomes in practice.
| Evaluation Criterion | Automated Lineage (e.g., Manta, Octopai) | Manual/Catalog-Driven Lineage (e.g., Collibra, Alation) |
|---|---|---|
| Primary Goal | Technical troubleshooting & impact analysis | Business governance & compliance |
| Granularity | Column-level, highly detailed | Table-level, high-level & conceptual |
| Scalability | High; scales with the complexity of the data stack | Low; scales with the size of the governance team |
| Accuracy | High; reflects the “as-is” technical reality | Dependent on human upkeep; becomes stale |
| Setup Effort | High initial configuration, low maintenance | Low initial setup, high ongoing maintenance |
| Key User | Data Engineer / Analytics Engineer | Data Steward / Business Analyst / Auditor |
| Context | Technical context (code, queries, transformations) | Business context (glossary, policies, ownership) |
If your team is bogged down by broken pipelines, production incidents, and uncertainty about the impact of code changes, an automated, parser-based tool is the correct choice. If your primary driver is building an enterprise-wide governance framework and proving compliance to auditors, a catalog-driven approach provides the necessary business-level context, but you must be prepared for the significant manual effort required to maintain it.
Comparing Critical Capabilities for the Modern Data Stack

The value of a data lineage tool is not measured by the number of connectors it has, but by the depth of its integration with the platforms you use every day. Shallow, table-level lineage for critical systems like Snowflake, Databricks, BigQuery, dbt, and Airflow is operationally useless. Your evaluation must focus on how a tool handles the messy realities of your stack. True integration means a tool can parse Snowflake’s complex query history to trace data movement, not just list which tables were involved.
Differentiating by Platform Integration Depth
This is where a real data lineage tools comparison begins. Test vendors against the specific nuances of your environment. A tool’s ability to correctly parse column-level lineage from a deeply nested dbt macro is a massive differentiator; many tools fail at this, unable to unpack the logic and map dependencies accurately. The same is true for orchestration. Tracing data through a complex Airflow DAG requires a tool to visualize dependencies between tasks and understand how data is passed between them.
The data lineage market is projected to grow at a 25.6% CAGR, a direct result of increasing complexity in modern data stacks. This growth underscores the need for platforms that can deliver end-to-end visibility and reduce governance overhead.
An Evaluation Framework for Stack Integration
Cut through marketing claims with a structured evaluation of each tool’s performance in your actual stack. Score every potential vendor against these critical criteria:
- Connector Maturity: Does the tool offer basic connectivity, or can it parse complex, platform-specific logic like Snowpark UDFs or Databricks notebooks?
- Granularity of Capture: Can it reliably deliver column-level lineage for your most important platforms, or does it degrade to table-level lineage when transformations become complex?
- Support for Platform Features: How well does it handle unique capabilities like Snowflake Streams, the Databricks Unity Catalog, or dbt exposures?
- BI vs. Processing Support: Some tools excel at tracing lineage into BI platforms like Tableau but are weak on the data processing side with Spark or Airflow. Identify which part of the stack is your priority.
A strong data lineage tool is essential for generating reliable audit evidence and maintaining compliance. Rigorously testing these capabilities ensures you match a vendor’s true strengths to your technical needs, resulting in actionable insights, not just another dashboard.
Mapping Tools to High-Value Engineering Use Cases

A data lineage tool without a clear problem to solve is an expensive diagramming utility. Its value is realized only when it directly resolves a critical pain point for your engineering or business teams. The evaluation process must map tool capabilities directly to your organization’s highest-priority use cases.
Match the tool’s architectural strengths to your specific, high-stakes scenario.
Use Case 1: Operational Root Cause Analysis
A critical executive dashboard breaks at 3 a.m. The on-call engineer must find the root cause immediately. They do not need a business glossary; they need deep, technical, column-level lineage to trace an anomaly back through a maze of transformations.
Automated, parser-based tools are built for this moment. Platforms like Manta excel at providing granular visibility into the data stack, parsing SQL queries, dbt models, and ETL jobs. They are designed for engineers to debug broken pipelines by showing the precise point of failure in the code. When incident response is the priority, favor tools offering detailed, code-aware lineage over those focused on high-level business context.
Use Case 2: Enterprise Data Governance and Compliance
The primary goal is not firefighting but satisfying auditors, proving compliance with regulations like GDPR, and building a trusted enterprise data dictionary. This job is less about code and more about connecting technical assets to business meaning.
Catalog-first platforms like Collibra are the standard for this use case. These tools are purpose-built to link physical data assets to the business glossary, data owners, and governance policies. The lineage is often conceptual—at the table level—but it provides the crucial business context that compliance and governance teams need for reporting and audits.
Use Case 3: Change Impact Analysis
Your team is about to deploy a schema change and needs to know what it will break downstream. This use case is about proactive risk management—preventing broken dashboards and failed pipelines before they happen.
Tools with a strong focus on impact analysis, such as Alation, are a direct match. They give engineers the ability to simulate the ripple effects of a proposed change. By showing exactly which reports, ML models, and data products will be affected by a column modification, they allow teams to coordinate changes safely and avoid production failures.
Your Actionable Evaluation Framework and RFP Checklist
Choosing the right data lineage tool is a significant investment that demands a structured evaluation. Move past vendor demos and use a detailed Request for Proposal (RFP) to put each tool through its paces. This checklist contains over 20 critical questions to compare tools apples-to-apples and identify the right fit for your data stack and business needs.
Technical and Integration Capabilities
This is where you determine if the tool can handle your environment. Vague answers from vendors are a major red flag.
- Lineage Capture Method: How is lineage captured? Is it by automatically parsing query logs and code, or does it rely on manual declaration?
- Granularity: Does it provide true column-level lineage or just table-to-table flows? Demand proof.
- Platform-Specific Parsing: How well does it interpret the reality of your stack, such as complex dbt macros, historical Snowflake queries, or lineage within the Databricks Unity Catalog?
- API Access: Is there a well-documented API for programmatic access to lineage metadata?
- Real-Time Support: Can it handle streaming data? Ask how it visualizes lineage from sources like Kafka.
- Extensibility: Can your team write custom parsers for proprietary or unsupported data sources?
Governance and Security
A lineage tool holds the map to your data kingdom and must comply with your security and governance rules from day one.
- Role-Based Access Control (RBAC): Can you restrict visibility for sensitive data pipelines or metadata based on user roles?
- Identity Provider Integration: Does it integrate with your SSO provider (e.g., Okta, Azure AD)?
- Audit Trails: Does the platform log all user actions and changes to lineage?
- Policy Integration: Can you link an asset’s lineage directly to its data classification, owner, or access policies?
Usability and Adoption
A technically powerful tool is worthless if your team will not use it. User experience is as critical as the back-end engine.
- Visualization Quality: Is the lineage graph clean, navigable, and insightful, or is it just “eye candy”?
- Search and Discovery: During a production incident, how quickly can an on-call engineer find a broken asset and trace it back to its source?
- Collaboration Features: Can users add comments, tag owners, or certify assets as “trusted” within the tool?
According to DataEngineeringCompanies.com’s analysis of 86 data engineering firms, a common failure point is a tool that produces technically accurate but unusable lineage graphs. If your engineers can’t quickly find what they need during an incident, the tool has failed. For a deeper dive, our guide on building a data-driven RFP process provides best practices for assessing how a tool will perform in the real world, not just in a sales pitch.
Making the Final Decision: A Clear Path Forward
After evaluating features and architectures, the decision comes down to your primary goal. This choice creates a fork in the road, splitting your evaluation path into two distinct directions.
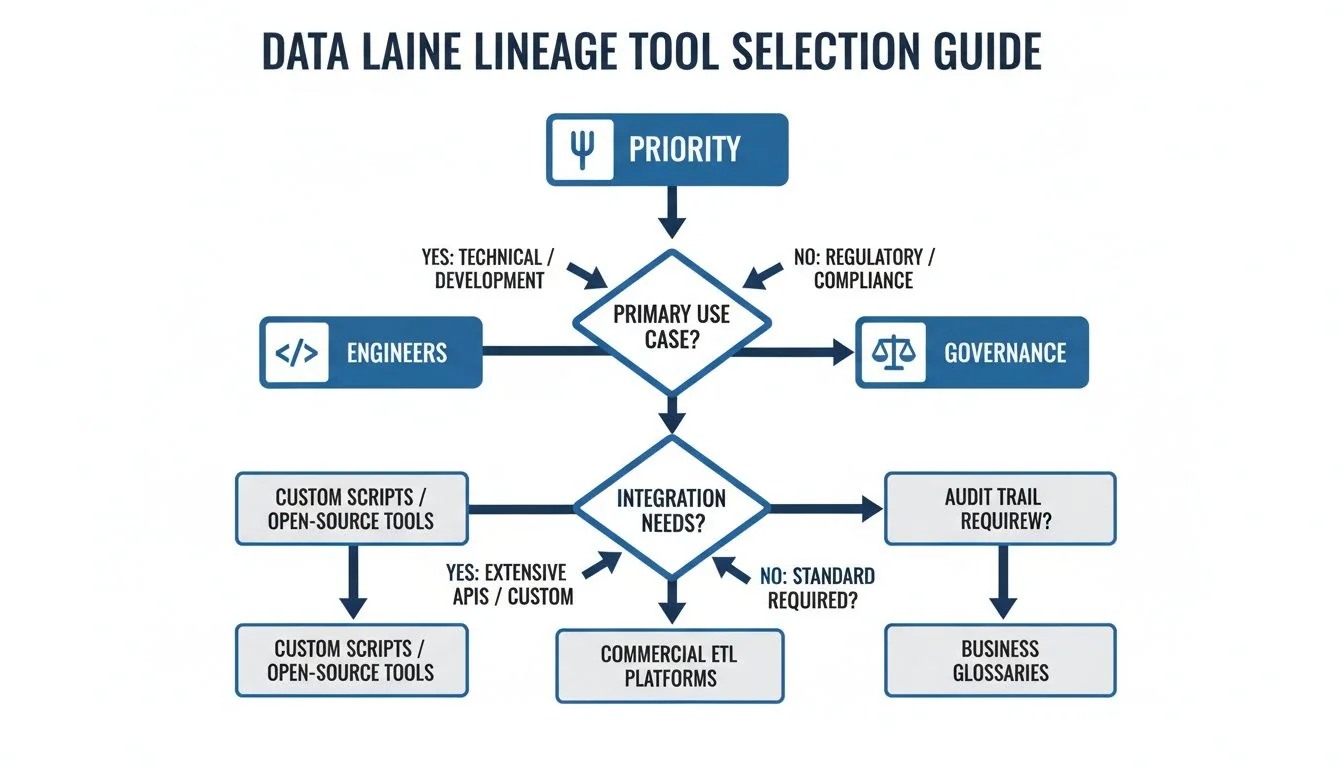
The flowchart clarifies the decision: you are either starting with the needs of your data engineering team or with the requirements of your enterprise governance program.
Engineer-Centric vs. Governance-Centric Paths
If your main priority is giving data engineers deep, technical visibility to fix broken pipelines and debug code-heavy environments like dbt or Airflow, your best bet is a tool with an automated, parser-based architecture. A solution like Manta shines here, delivering the granular, column-level detail that engineers need for quick root cause and impact analysis.
On the other hand, if your driving force is to establish an enterprise-wide governance framework and keep auditors happy, then a catalog-first platform like Collibra makes the most sense. These tools are built to connect technical metadata to business glossaries and policies, giving you the high-level, contextual lineage essential for compliance.
Your Immediate Next Steps
Analysis paralysis is the biggest impediment to making a decision. A hands-on evaluation provides a clear path forward.
- Define Your Top Two Use Cases: Select one highly technical use case (e.g., debugging a specific, troublesome pipeline) and one business-focused use case (e.g., certifying a critical regulatory report).
- Run a Focused Proof of Concept (POC): Do not try to boil the ocean. Choose one vendor from each category—one parser-based and one catalog-first—and test them against a single, challenging data pipeline in your own environment.
- Score the Results: Use the RFP checklist from the previous section to score how each tool performed on your specific use cases.
This approach delivers undeniable proof of which architecture will bring the most value to your team. It transforms a theoretical debate into a decision based on practical, real-world results.
Frequently Asked Questions
These are the most common questions engineering leaders face when evaluating data lineage tools.
What Is the Biggest Mistake When Choosing a Data Lineage Tool?
The biggest mistake is being impressed by a long list of connectors. A vendor might show a slide with 50 logos, but this is often marketing fluff. What matters is the depth of the connectors for the systems that are most critical to your business, whether that’s dbt, your main BI tool, or a core ETL orchestrator. A successful data lineage tools comparison requires digging deep. Does the tool provide only table-level lineage, or can it trace all the way down to the column level through complex logic? The quality of lineage from your most important sources determines the project’s success.
How Do Open Source Tools Like OpenLineage Compare to Commercial Vendors?
This is a classic build-vs-buy decision. Open-source frameworks like OpenLineage are powerful and flexible but are not a complete solution. They require a significant engineering commitment to implement collectors, build a user interface, and maintain the system. Commercial tools deliver value much faster with a polished UI, pre-built parsers, and enterprise support, in exchange for a license fee. Open source gives you total control but comes with a high total cost of ownership paid in engineering hours. A commercial tool accelerates time-to-value, assuming the price aligns with your budget.
Can a Data Lineage Tool Integrate with Both Snowflake and Databricks?
Yes. Most modern tools are built for a multi-cloud, multi-platform world. The real question is not if they can connect to both Snowflake and Databricks, but how well they stitch the lineage together across them. A simple test for your POC is to trace a single data flow from a Databricks job, into a Snowflake table, and finally out to a Tableau dashboard. Can the tool show you that entire journey as one seamless, unified graph? This common scenario is a frequent failure point for less mature platforms. Make vendors prove this capability.
Navigating the complex world of data engineering firms can be as challenging as selecting the right tool. DataEngineeringCompanies.com provides transparent, data-driven rankings of top consultancies to help you find the right partner for your Snowflake, Databricks, or cloud data projects. Find your expert data engineering partner with confidence.
Data-driven market researcher with 20+ years in market research and 10+ years helping software agencies and IT organizations make evidence-based decisions. Former market research analyst at Aviva Investors and Credit Suisse.
Previously: Aviva Investors · Credit Suisse · Brainhub · 100Signals
Top Snowflake Partners
Vetted experts who can help you implement what you just read.
Related Analysis

What is a semantic layer? A Practical Guide for AI and BI Data Unification
Discover what is a semantic layer and how it unifies data for AI and BI, including Snowflake and Databricks.

Snowflake Partners vs. Databricks Partners: Who Should You Hire in 2026?
Confused between hiring a Snowflake or Databricks partner? We compare the ecosystems, partner specializations, and how to choose the right expert for your data platform.

A Practical Guide to Data Management Services
A practical guide to selecting the right data management service. Compare models, understand pricing, and learn key implementation steps to drive ROI.